
How GPT Seamlessly Handles Multiple Languages, Math Notations, and Emojis
How GPTs Convert Text to Universal Tokens with UTF-8 & Byte Pair Encoding (BPE)


Ever wondered how models like ChatGPT read your message and respond so well?
It all starts with how text is converted into something called a token.
This post will walk you through exactly how GPT breaks down your sentence - from raw characters to 8-bit bytes to token IDs - with real code examples.
Let’s say you type: "hello 😊"
What happens inside GPT?
Step-1: Text to UTF-8 Encoding to 8-bit Bytes
Every character of your text is first turned into UTF-8 bytes, i.e., 8-bit numbers in the range 0–255. So, when you type "hello 😊", the following is generated:
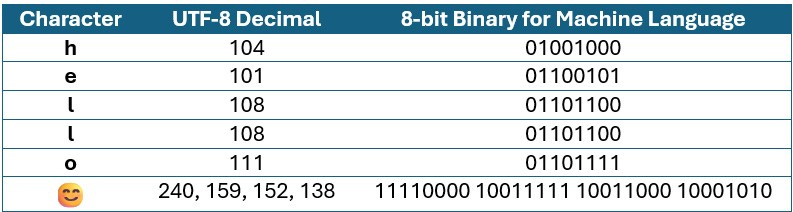
Try the snippet below in Python:
text = "hello 😊"
utf8_bytes = text.encode("utf-8")
print(list(utf8_bytes))
Output: [104, 101, 108, 108, 111, 32, 240, 159, 152, 138]Your text is converted to a byte stream as shown above, where each number is further converted to an 8-bit chunk. Emojis and non-English characters can take multiple bytes.
Step-2: Byte Pair Encoding (BPE)
Once we have byte sequences, GPT applies a clever trick called Byte Pair Encoding (BPE). It is a smart compression trick to merge frequent byte patterns into homogeneous groups.
How?
It finds frequent adjacent byte pairs and merges them into reusable chunks called tokens.
It continues merging to create a vocabulary of common chunks (like "the", "##ing", ".com", "😂", etc.)
Example:
('l', 'l') → 'll'
('e', 'll') → 'ell'
('h', 'ell') → 'hell'
('hell', 'o') → 'hello' and so on.
You can use OpenAI’s tokenizer (tiktoken) to see this in action:
import tiktoken
enc = tiktoken.get_encoding("gpt2") # other tokenizer: "cl100k_base"
tokens = enc.encode("hello 😊")
print(tokens) # Token IDs
print([enc.decode([t]) for t in tokens]) # Token strings
Output:
[15496, 220, 96050]
['hello', ' ', '😊']So, here GPT replaces:
"hello" with token 15496
" " with token 220
"😊" with token 96050
These are tokens, not characters or bytes anymore.
Step-3: Assign Each Token a Number (ID)
GPT doesn't store text - it stores token IDs.
So ['hello', ' ', '😊'] is represented as [15496, 220, 96050].
Token IDs depends on the specific tokenizer vocabulary.
The above byte-to-token process is efficient as:
Handles all languages and emojis
Takes fewer tokens than characters or words
Compact and finite vocab
Final Output:

Step-4: Token IDs as Model Input
These token IDs are now passed into the GPT model for further processing, learning, or generation.
So, input to model would be: [15496, 220, 96050]
That’s all GPT needs to predict the next word, translate, summarize, or write code.
Token Vocabulary: Pre-Built and Reused
Before training, GPT builds a fixed vocabulary of frequent byte patterns using BPE on large text datasets. This vocabulary and merge rules are saved and not updated later.
During inference, GPT:
Converts text to UTF-8 bytes
Applies the same BPE merge rules
Uses the same token vocabulary
Merging stops when no further valid merge is found in the pre-built dictionary.
This ensures consistent tokenization for all inputs.
Different GPT models use different tokenizers with fixed vocabulary sizes. For example, GPT-2 and GPT-3 use BPE with ~50K tokens, GPT-4 uses a newer BPE with 100K+, and LLaMA uses SentencePiece with ~32K tokens.
What Happens During Inferencing?
First, universal tokens are generated during training and stored in a fixed vocabulary.
Later, when you provide text, the tokenizer matches it against this vocabulary and represents it as a sequence of token IDs.
Below is a Python implementation of the above logic during inference:
import tiktoken
# Use a tokenizer #gpt2, cl100k_base
enc = tiktoken.get_encoding("gpt2")
# Input sentence
text = "machine learning is fun!"
# Tokenize using BPE
tokens = enc.encode(text)
decoded = [enc.decode([t]) for t in tokens]
# Display
print("Original text:", text)
print("Token IDs:", tokens)
print("Tokens:", decoded)You can try the above code to tokenize your own texts.
Why Can’t ASCII Do This?
ASCII is a 7-bit system from the 1960s.
It works for English A–Z, a–z, digits, and punctuation.
But it breaks when you use:
Emojis like 😎
Accented letters like “é”
Non-English scripts like Hindi, Chinese, Arabic
Example:
text = "नमस्ते"
print(text.encode("ascii")) # 🚨
Output:
UnicodeEncodeError: 'ascii' codec can't encode characters...But with UTF-8:
print(list(text.encode("utf-8")))
Output:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164, 224, 165, 135]Summary
So, your text is turned into UTF-8 bytes, merged into tokens with BPE, and mapped to token IDs.
That’s why it works across all languages, symbols, and emojis and is truly language-agnostic and internet-friendly.
ChatGPT doesn’t actually read words or emojis. It reads numbers using the available tokens. Because of the universal tokenizer, it’s possible to represent all possible language texts, emojis, and even math notations. And for that rare or unusual text(s) it will take more tokens to represent.
Finally: Text --> UTF-8 bytes --> BPE merges --> Tokens --> Token IDs.
A Python implementation is shown here. The code is also available in GitHub.